This presentation by Martin Fowler gives a broad overview of NoSQL. It's perfect for newcomers to NoSQL, and also for those seeking a perspective from which to view the myriad recent developments under the nebulous umbrella 'NoSQL':
As always, I'll briefly summarize what I think are some of the salient points in the video, to make it easier to digest at a glance. For the purposes of this article, you will need to have a working knowledge of Relational SQL databases, and OO code.
Object databases
First, Martin places NoSQL in a DB popularity timeline:
- 80's - rise of Relational
- 90's - critical success but commercial failure of Object databases
- 00's - rise of NoSQL alongside Relational
Object DBs make a huge amount of sense for OO application development. The Object DB disk storage paradigm matches the in-memory paradigm of hierarchical object relationships, making the impedance mismatch disappear. The security, transaction and querying features are comparable to Relational. So why the commercial failure?
Martin puts it down to the larger ecosystem - it's a common requirement that the new DB you are creating be accessible by existing reporting tools, or multiple other pre-existing applications. Different departments will want to access your data, and they are loaded with Relational/SQL experts.
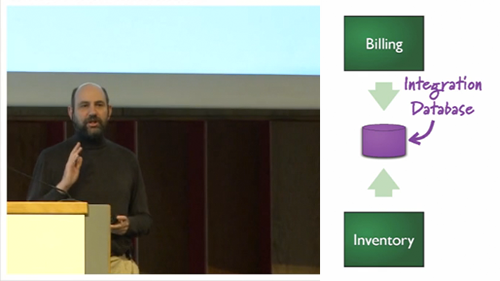
Object DBs use much simpler SQL for data access, and it is incompatible with the JOIN-heavy SQL used in Relational DBs.
In this scenario it makes sense to stick with a single DB paradigm - the existing, trusted, proven Relational - and just let the OO application developers deal with impedance mismatch via ORM.
Lots of data => distributed data => NoSQL
Martin goes on to say that in the early 2000's when Google and Amazon were considering how to deal efficiently with massive scale, it became clear that there wasn't a computer big enough in the world to house all that data. The only option was to store it on multiple computers, and large distributed networks. Bigtable and Dynamo were born.
The term 'NoSQL' is almost an accidental term and doesn't really tell you anything about the characteristics of the technologies. Loosely clustered within this label are the following:
- Non-relational - not all, but generally
- Open source - not all, but generally
- Cluster friendly - the initial driver, but now just one aspect
- 21st Century web - are DBs with similar characteristics from pre-2000 part of this group? - no.
- Schema-less - again, not all, but generally. And note that in reality there is always a schema - it just means there is an implicit schema, rather than an explicit one.
The label 'NoSQL' is terrible, because the characteristics described above don't lead you to it. NoSQL is just a catch-all, and when you look at the different things that people mean when they say it, you end up something like with the characteristics above.
Commonly discussed types
Here we have an outline of the most often-discussed types, and some sample implementations:
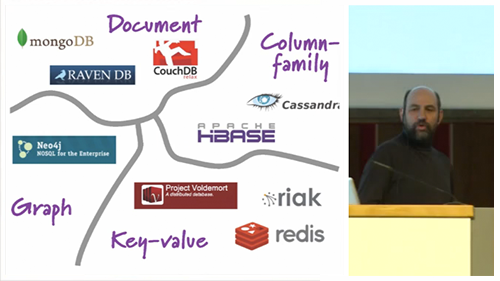
Things are missing here, and at the end one of the audience members asks about different types. Martin gives a very interesting answer illustrating what he thinks might happen with respect to the future of DBs. But for the purposes of this introductory presentation, these are the types we are discussing.
Aggregate-oriented data models
When using an ORM to access a traditional relational DB we are declaring that we want some aggregate of data. That aggregate may involve a lookup from some CountryID to the name of an actual country, or to all sorts of other data types in other tables, perhaps several Foreign Keys down the chain.
The concept of aggregate here is taken from Eric Evans' Domain-Driven Design. The insight added is that in Key-Value, Document and Column-family DBs, a key is used to access an aggregate of data. The given DB is 'aware' of the aggregate in a way that Relational DBs are just not aware, and therefore the aggregate can be distributed as a unit, improving performance over massive datasets.
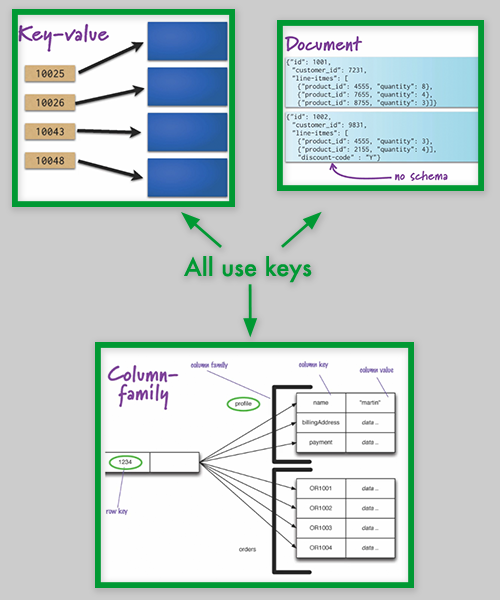
Note the trade-off - what if you don't want to access that data as an aggregate? What if you want to know the average age across all Customer records? Now you have to access loads of aggregates across loads of distributed nodes.
But where is the mission-critical part of your business? Is it in running a report like that? Or is it in quickly retrieving aggregated records?
Graph DBs are different
The next section illustrates how Graph DBs are different, and affirms the oddness of grouping all of these DBs under the term 'NoSQL'.
Check out this explanation if you are not familiar with the acronyms ACID and BASE. Martin points out that in many respects, Relational DBs are not ACID anyway. For example, transactions are not designed to remain open across entire internet browsing sessions where two people are considering purchasing the same item.
However, within the framework of ACID and BASE, the three Aggregate-oriented DBs are BASE where the Graph DB is ACID:

Part of that BASE acronym may be unfamiliar to you - what is Eventual Consistency? To get an idea, this article contains a great Introduction to the CAP theorem, in Plain English. Explanation by analogy is one of my favorites!
Problems with CAP
Understanding the CAP theorem is important, because it tells you about the trade-offs you are making when you consider a NoSQL DB.
However, it should be noted that for the vast majority of projects, CAP need not apply. Massive, distributed data may have been one of the initial drivers for NoSQL's existence, but that was just the 'crack'. Now there are all kinds of other reasons, for example the ease of development, the reduction of impedance mismatch, the alignment with particular types of data storage paradigms.
But unless, like the very few, you really do have to have massively distributed data, then CAP is meaningless. You can forego the Partition Tolerance and be happy with the Availability and Consistency.
When to use (and NOT use) NoSQLThere are two main drivers (and one more - the middle one below - is implied):
- Large scale data - the thing that kicked off NoSQL in the first place
- The paradigm works - as in the case of Graph DBs, if the data storage paradigm better mirrors your purposes
- Easier development - simpler data access, just like Object DBs promised in the 90's
For the mostpart now, the reason people are using NoSQL DBs is the last one - easier development. So again, in most cases, where you don't have large volumes of data, the CAP issue doesn't really apply. Which begs one more question...
Why NoSQL now?
So why is NoSQL taking off where Object DBs failed? Martin posits that the original blocker has faded due to a happy coincidence.
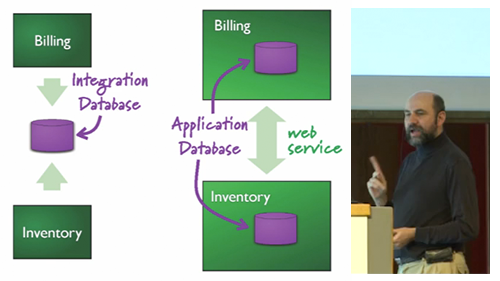
The rise of the popularity of RESTful web services has meant that there is no longer a need for systems to integrate with databases directly. A datastore can be exposed via a standardized REST interface, abstracting the underlying storage implementation.
As ever, when I see an interesting video I sometimes like to summarize it for my own sake. All of the arguments put here derive from the video and I have included no original research. I just sometimes like to write up a few notes to look back on later, and share in case you find it useful too!