I've heard a little about ambisonics from sound artists, but now that we are going to attempt to use it at Jaaga, I decided to go back to basics. Here are the results.
Introduction
First, I searched Youtube for a gentle intro. This 'man-in-white-coat' video from the EBU is perfect. In it, the 3D sound concept behind ambisonics is introduced and discussed.
They also introduce the notion of first-order (4-channel) vs. higher-order (multichannel) ambisonics, and mention ambisonic's lack of compatibility to 2-channel sound. They say that in first-order ambisonics, just 4 audio channels can be interpreted to give "any number of loudspeaker signals that we need", but they don't explain how.
Advantages and Disadvantages
To get a little further, I went to Wikipedia. Here we have a nice list of advantages and disadvantages, which i'll paraphrase:
Advantages
- Sounds from any direction are treated equally (not favouring front & side - i.e. it's isotropic), leading to better soundfield 'imaging'
- A minimum of 4 channels are required (first-order)
- Loudspeakers do not have to be arranged in a rigid setting, thier placement can vary (within 'sensible' limits)
- The ambisonic signal is independent of the replay system - i.e. you can record / synthesize once and replay on any ambisonic-compatible loudspeaker arrangement
Disadvantages
- Not supported by any major label or media company - never marketed, largely unknown outside academic circles
- Conceptually different to traditional 1 speaker per setup approaches, so small learning curve
- Needs to be decoded from storage format (called B-Format) into your loudspeaker environment. Hardware boxes or software can do this.
- Number of speakers vs. size of space: "... if the listening area is too large then, without treatment, the resulting soundfield can approach the limits of stability. This has resulted in some unimpressive demos"
B-format and Channel Roles
Later in the article it describes how the storage format works and what each channel does:
"[In first-order Ambisonics], sound information is encoded into four channels: W, X, Y and Z. This is called Ambisonic B-format. The W channel is the non-directional mono component of the signal, corresponding to the output of an omnidirectional microphone. The X, Y and Z channels are the directional components in three dimensions. They correspond to the outputs of three figure-of-eight microphones, facing forward, to the left, and upward respectively."
So with a four-channel file we have a mono channel and 3 positioning channels. What this doesn't tell me is exactly what data are stored in those three positioning channels, and how they are used to coax the information from a mono channel into a 3D space. I think I'm going to come back to this later though, I want to learn more about the listening space for now.
The Listening Space
The first thing on my mind is, how does B-Format translate into the listening space? Is B-Format enough to allow multiple moving sounds to move separately throughout the space, or only one?
I came across an excellent set of tutorials by a guy named Bruce Wiggins from University of Derby, UK. There are five videos, each in lecture / presentation style, designed for the beginner, which is perfect. The presentations talk in reference to a software product called Reaper, which even if we don't use, is interesting all the same.
One of the presentation screens contains a diagram that seems to answer my question:
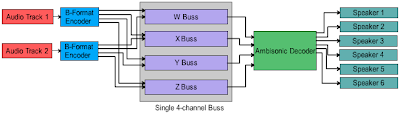
This diagram shows how to encode separate audio tracks to a single B-Format file, and then how to decode that file into a multichannel listening space. In Bruce's words:
"During the encoding process each source is panned, and then sent to [an encoder bus] where it is summed with the other panned sources, decoded, and then sent to the speakers.
The videos continue into practical sessions.
Decoding and Encoding
Bruce begins by creating a track for the decoder. He sets it to be a 4-channel in, 8-channel out track and routes each output to a loudspeaker. He attaches a VST plugin to do the decoding from a 4-channel B-Format bus to the 8-channel listening space. (Bruce then switches to quad out for demo purposes over a stereo video, but the principal is there.)
The next stage is to add B-Busses, again as separate tracks, and to connect them to the decoder using Sends. In this case he creates a track for a reverb send, a track for the original 'dry' recording, and a track to sum the two together ready for the decoder.
Finally, Bruce creates a track representing a mono-in, and attaches a VST Encoder so that it outputs in B-Format. He then Sends this track to the dry / reverb B-Busses.
This answers a question I had been mulling over - given a mono audio track, where does the pan information come from? In this case, the pan information is added to the mono track via the VST Encoder plugin interface. You could add it in real-time, record it, or automate it. This is because we are encoding from a mono source - if you were using ambisonic recordings, the hardware would have written the B-Format for you and you wouldn't need an Encoder.
Questions
That's enough for an intro. The questions it leaves me pondering:
- Notably all of Bruce's decoder options assume a specific (and quite lab-oriented) loudspeaker setup, i.e. a perfect octagon with all speakers at a specific angle. I will have to look further into how to handle much more 'random' listening spaces.
- Similarly, the panning options in his VST encoder use Azimuth and Elevation. It seems that in order to get a nice 3D effect more appropriate options would be X, Y and Z co-ordinates? However it may be that the controls provided here are enough.
- Less important immediately, but how do the B-Format XYZ busses relate to the W bus? What data specifically do they store? And for example, if Audio Track 1 and Audio Track 2 contained the same frequencies but were in different XYZ locations, how does the mixdown process work? I have a feeling the answer may be 'just the same as mixing in stereo', but it's hard after years of thinking in terms of two channels to immediately make that leap, and I need to get into the XYZ bus data to really get that.
- What changes when we delve into higher-order ambisonics? Does this improve the 'resolution' or some other factors aswell?
- And ofcourse, what are the different ways of working associated with other applications / plugins / environments, i.e. Max/MSP? I think this is the next question to answer, as I have a feeling that exploring that will answer some of the questions above.
See the follow-up article here: Going Further with Ambisonics